tricking sand into thinking
deep learning in clojure with apache mxnet

@daveliepmann

TRICKING SAND INTO READING



(defn get-symbol []
(as-> (sym/variable "data") data
(sym/fully-connected "fc1" {:data data :num-hidden 128})
(sym/activation "relu1" {:data data :act-type "relu"})
(sym/fully-connected "fc2" {:data data :num-hidden 64})
(sym/activation "relu2" {:data data :act-type "relu"})
(sym/fully-connected "fc3" {:data data :num-hidden 10})
(sym/softmax-output "softmax" {:data data})))TRICKING SAND INTO WRITING POETRY


(defn lstm [num-hidden in-data prev-state param seq-idx layer-idx dropout]
(let [i2h (sym/fully-connected (str "t" seq-idx "_l" layer-idx "_i2h")
{:data in-data :weight (:i2h-weight param)
:bias (:i2h-bias param) :num-hidden (* num-hidden 4)})
h2h (sym/fully-connected (str "t" seq-idx "_l" layer-idx "_h2h")
{:data (:h prev-state) :weight (:h2h-weight param)
:bias (:h2h-bias param) :num-hidden (* num-hidden 4)})
gates (sym/+ i2h h2h)
slice-gates (sym/slice-channel (str "t" seq-idx "_l" layer-idx "_slice") {:data gates :num-outputs 4})
in-gate (sym/activation {:data (sym/get slice-gates 0) :act-type "sigmoid"})
in-transform (sym/activation {:data (sym/get slice-gates 1) :act-type "tanh"})
forget-gate (sym/activation {:data (sym/get slice-gates 2) :act-type "sigmoid"})
out-gate (sym/activation {:data (sym/get slice-gates 3) :act-type "sigmoid"})]
(lstm-state (sym/+ (sym/* forget-gate (:c prev-state))
(sym/* in-gate in-transform))
(sym/* out-gate (sym/activation {:data next-c :act-type "tanh"})))))The joke o Iso nt thoo ief s o se lds , por rs e maa tyoir at oro slk i lely eerre Whoethaaliis e tthoo o actitoou msea to utsu , s t ratthhee oainrgielnearip er pte e r da int htahoe
The joke schools to open health care and every child or whether or children at a single party that makes America adved-us to callying as new technology to early halfalishs of the wares.TF
TRICKING SAND INTO MORE EXAMPLES
TRICKING SAND INTO SEEING



(thanks to contributors Kedar Bellare and Nicolas Modrzyk)
TRICKING SAND INTO PAINTING
Neural Style Transfer






TRICKING SAND
WITH CLOJURE


"Large research groups [have the resources] to tune models on 450 GPUs for 7 days"

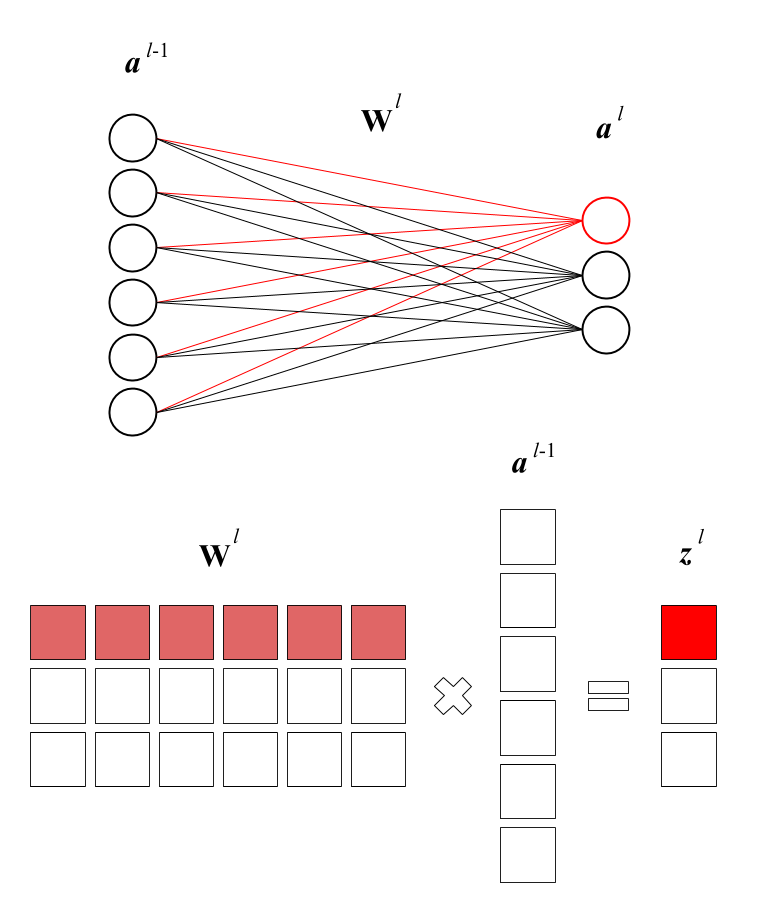
TRICKING SAND INTO
FAST LINEAR ALGEBRA


BLAS: Basic Linear Algebra Subprograms

LAPACK: Linear Algebra PACKage
Access to BLAS/LAPACK
- Python: NumPy (1995)
- Python: SciPy (2001)
- Julia: since birth (2012)
JVM access to BLAS/LAPACK
- interop: f2j
- Neanderthal
- Clatrix
- MXNet
- Deep Learning for Java / DL4CLJ



HELP WANTED
- use it!
- add examples
- debug/improve existing examples
- port new functionality
- write documentation & guides

thanks!
- Carin Meier & Apache MXNet contributors
- Racket & Pollen (these slides are a lisp program)
- Winner's Curse? paper by Sculley, Snoek, Rahimi, Wiltschko
- Machine Learning for Artists, Gene Kogan (MNIST example)
- Backpropagation from the beginning, Erik Hallström
TRICKING SAND INTO EXTRA SLIDES
 Open source, distributed, deep learning library for the JVM
Open source, distributed, deep learning library for the JVM(def model
(-> (Word2Vec$Builder.)
(.minWordFrequency 5)
(.iterations 1)
(.layerSize 100)
(.seed 42)
(.windowSize 5)
(.iterate (BasicLineIterator. "resources/raw_sentences.txt"))
(.tokenizerFactory (doto (DefaultTokenizerFactory.)
(.setTokenPreProcessor (CommonPreprocessor.))))
(.build)))(.getWordVectorMatrix model "day")
;; #object[org.nd4j.linalg.cpu.nativecpu.NDArray 0x59073fb5 "[0.41, 0.21, 0.15, -0.21, -0.04, -0.40, -0.12, -0.10, -0.32, 0.35, 0.21, 0.28, 0.12, -0.07, 0.05, -0.07, -0.20, 0.21, 0.14, -0.15, 0.07, 0.20, 0.42, -0.23, 0.10, -0.40, 0.11, -0.42, -0.19, -0.11, 0.29, -0.00, 0.46, -0.51, 0.14, -0.23, 0.08, -0.21, -0.07, 0.10, -0.31, -0.19, 0.11, 0.21, -0.07, -0.12, -0.47, -0.16, 0.16, -0.14, 0.28, 0.04, 0.24, -0.14, -0.35, 0.09, -0.24, -0.07, 0.16, -0.46, -0.28, -0.01, 0.15, 0.43, 0.16, 0.04, 0.04, 0.19, -0.25, -0.35, 0.24, -0.06, 0.18, -0.01, -0.03, 0.10, 0.06, 0.11, 0.13, 0.04, -0.03, -0.19, -0.45, 0.12, -0.00, 0.04, 0.17, -0.34, -0.03, -0.18, -0.11, 0.01, 0.15, -0.06, -0.19, 0.25, 0.01, 0.28, -0.32, -0.11]"]MXNet vs DL4J?
IS MIR EGAL.

Timeline
- 1995 - Numpy (as Numeric)
- 1999 - f2j (*)
- 2001 - SciPy
- 2006 - Numpy
- ...
- 2014 - DL4J
- 2015 - TensorFlow, Keras, MXNet
f2j performance

Automatic translation of Fortran to JVM bytecode, Keith Seymour and Jack Dongarra 2003